Runtime: Intel Core i7-2600 Processor
Comments:
- Updated: MTJ, la4j, JBlas, CommonsMath, ojAlgo, EJML, UJMP, Jama
- MTJ now includes a native version (MTJ-N) and has many internal changes
- Removed UJMP-Native since the version on the website doesn’t contain native code apparently
- Summary results now define a small matrix as having a width/height of 10 instead of 4
- For MTJ-N to have the performance shown here, be sure to use optimized native libraries.
Links to the results:
Test Environment
| Date | 2013 / 10 |
|---|---|
| OS | Mint 14 64bit |
| Kernel | 3.5.0-17-Generic |
| CPU | Core i7-2600 3.4 GHz - 4 cores - 8 threads |
| RAM | 11 G |
| CPU Cache | 8194 KB |
| JVM | Java HotSpot(TM) 64-Bit Server 1.7.0_17 |
| Benchmark | 0.10 |
| Libraries | Version |
|---|---|
| Colt | 1.2 |
| Commons Math | 3.2 |
| EJML | 0.23 |
| Jama | 1.0.3 |
| JBlas | 1.2.3 |
| la4j | 0.4.5 |
| MTJ | 0.9.13 |
| OjAlgo | 34.8 |
| Parallel Colt | 0.9.4 |
| UJMP | 0.2.5 |
Summary Results
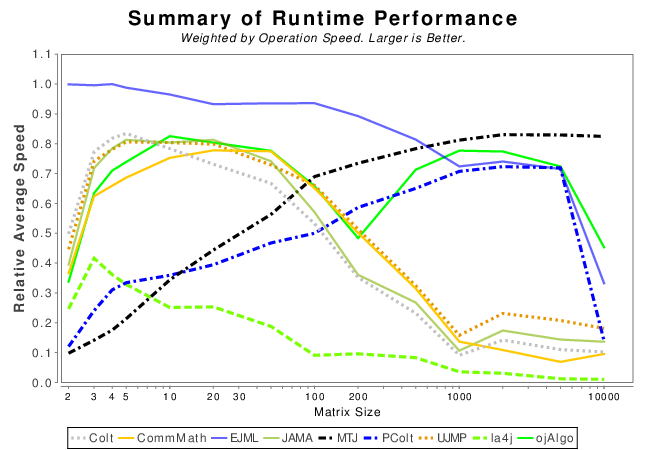
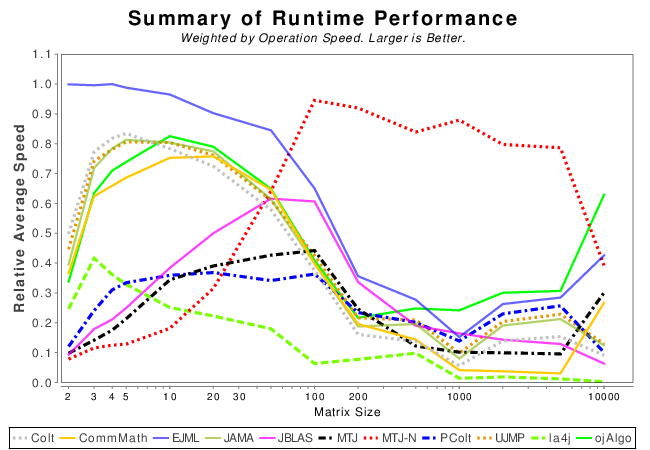
The following results are a weighted sum across all operations within each matrix size. Operations which take longer will have more weight. If a library could not finish an operation then its score is set to zero.
An artifact of “could not finish” approach is that libraries which do not support an expensive operation, barely time out, or run out of memory are significantly penalized. Results around the matrix size of 10k become erratic due to this issue.
__NOTE__ The weight is computed from the amount of time the fastest library takes to complete. Which is why the results change a bit from Java to Java + Native.
Pure Java Summary Results
Mixed Java and Native Summary Results
Pure Java Libraries
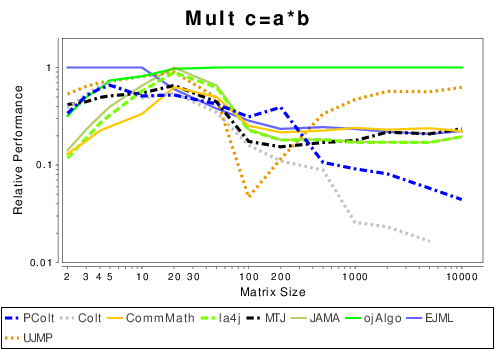
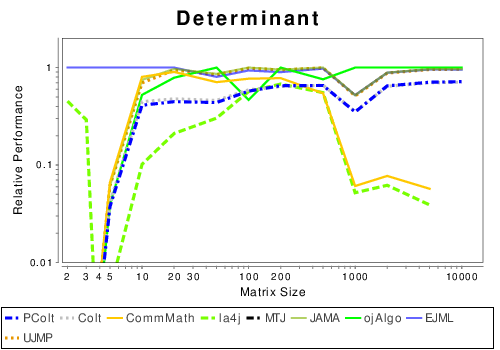
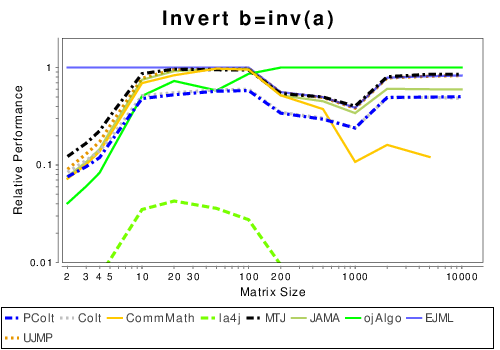
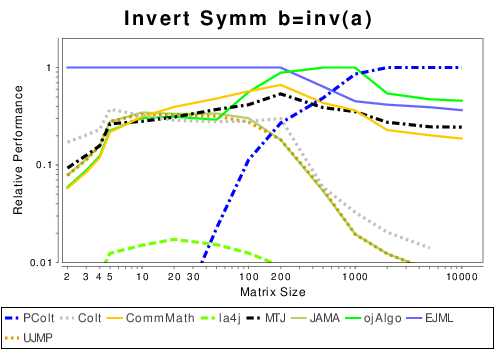
These results show the performance of libraries that have code written entirely in Java.
Java: Basic Operation Results
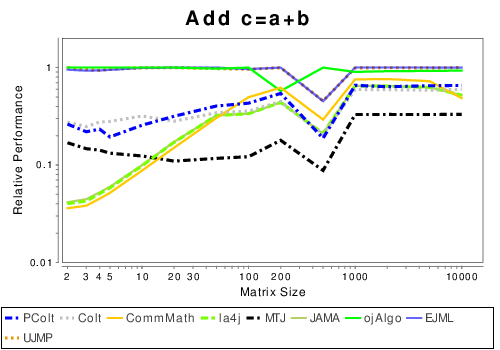 |
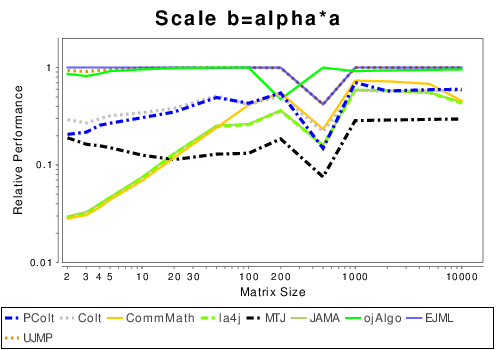 |
 |
|
 |
|
 |
 |
Java: Solving Linear Systems
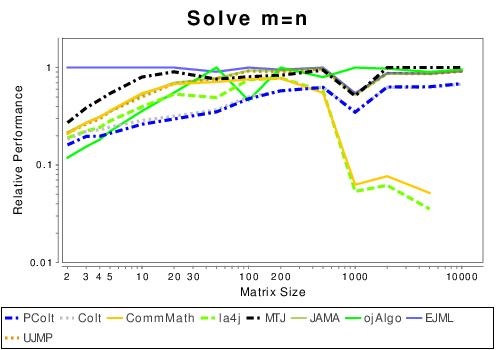 |
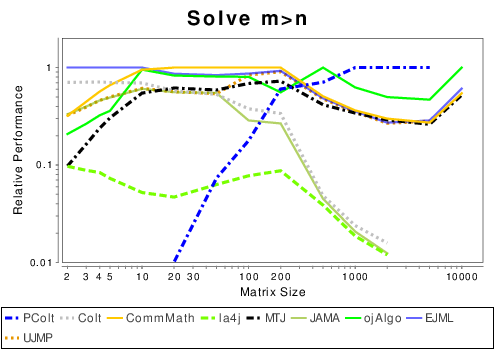 |
Java: Matrix Decompositions
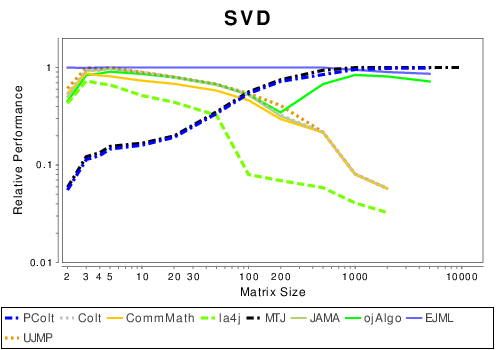 |
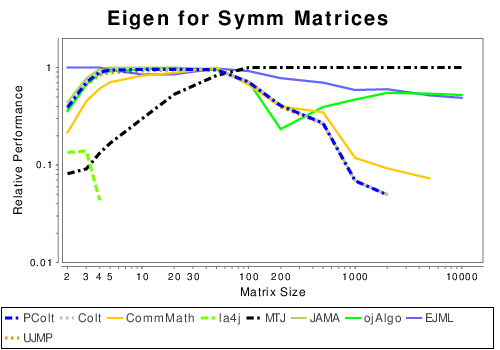 |
Mixed Java and Native Libraries
These results show the performance of libraries that either use pure Java or calls to native libraries.
Mixed: Basic Operation Results
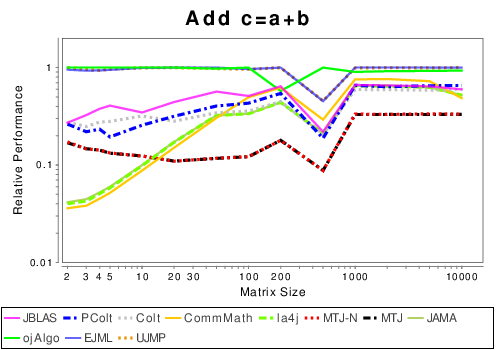 |
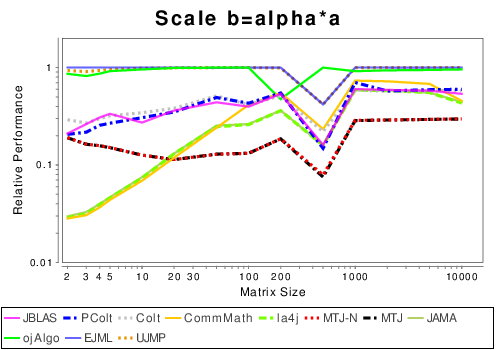 |
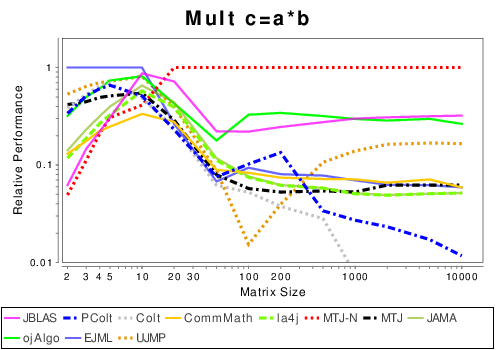 |
|
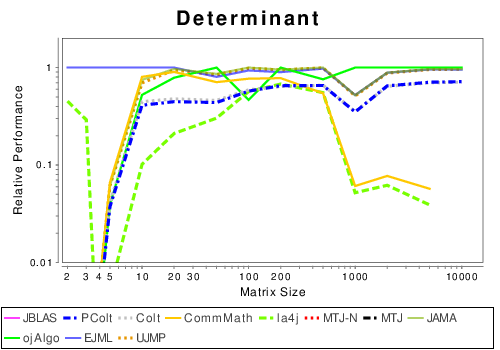 |
|
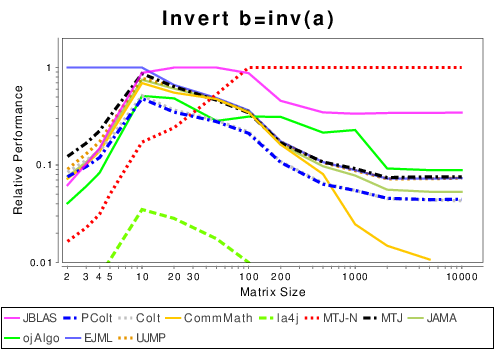 |
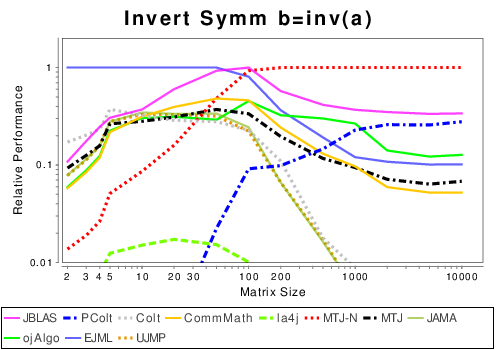 |
Mixed: Solving Linear Systems
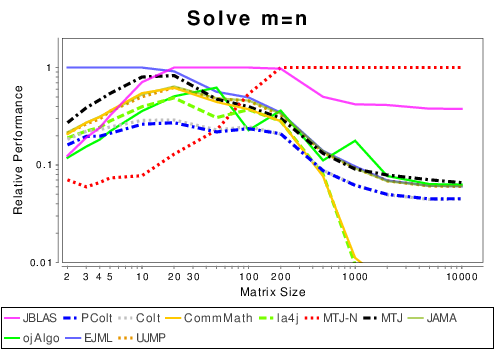 |
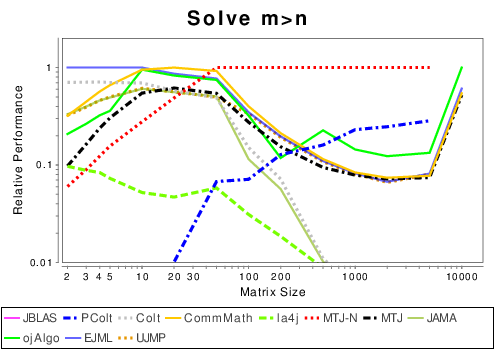 |
Mixed: Matrix Decompositions
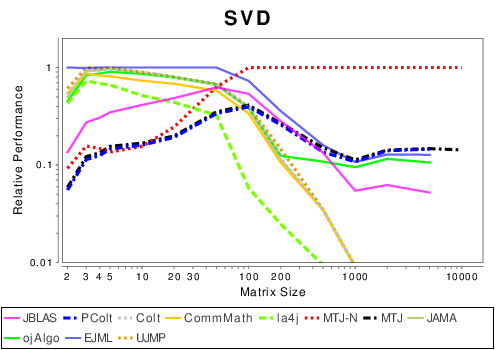 |
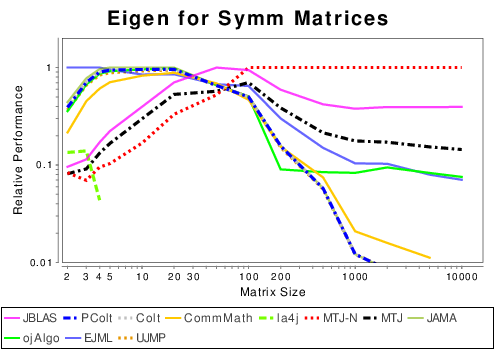 |