Runtime: 2.26 Ghz Intel Xeon
Comments:
- Parallel colt was ommitted due to some difficulties in running it
- Benchmark run by Anders Peterson
Links to the results:
Test Environment
UPDATE
| Date | 2015 / 07 |
|---|---|
| OS | Mac OS X 10.10.4 64-bit |
| CPU | 2x2.26 Quad-Core Intel Xeon. 16-threads |
| RAM | 12 G |
| CPU Cache | 8 MB L3, 256kB L2, 32kB L1 |
| JVM | Oracle Java HotSpot(TM) 64-Bit Server 1.8.0_45 |
| Benchmark | 0.10 |
| Libraries | Version |
|---|---|
| Colt | 1.2 |
| Commons Math | 3.5 |
| EJML | 0.27 |
| Jama | 1.0.3 |
| JBlas | 1.2.4 |
| la4j | 0.5.5 |
| MTJ | 1.0.3 |
| OjAlgo | 38.1 |
| UJMP | 0.2.5 |
Summary Results
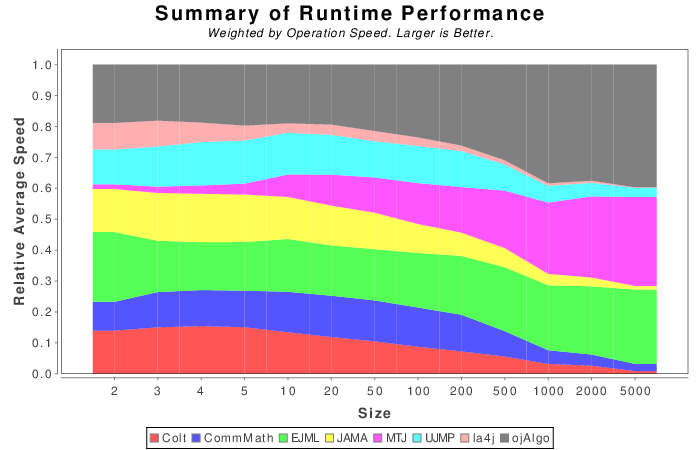
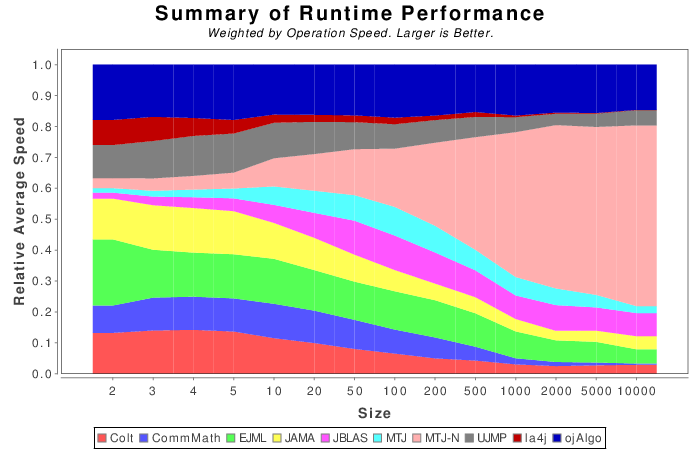
The following results are a weighted sum across all operations within each matrix size. Operations which take longer will have more weight. If a library could not finish an operation then its score is set to zero.
__NOTE__ The weight is computed from the amount of time the fastest library takes to complete. Which is why the results change a bit from Java to Java + Native.
Pure Java Summary Results
Mixed Java and Native Summary Results
Pure Java Libraries
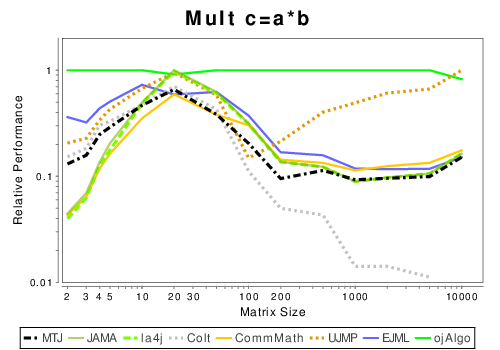
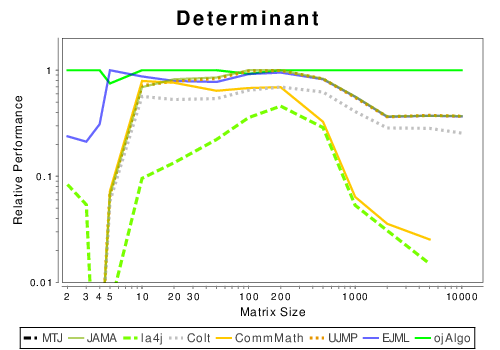
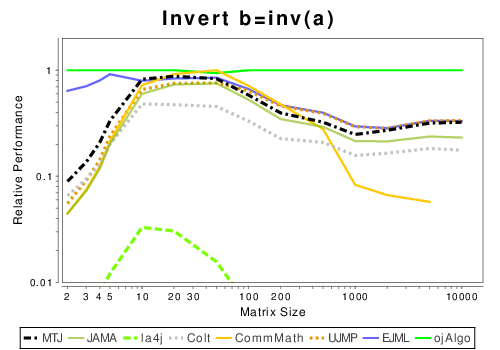
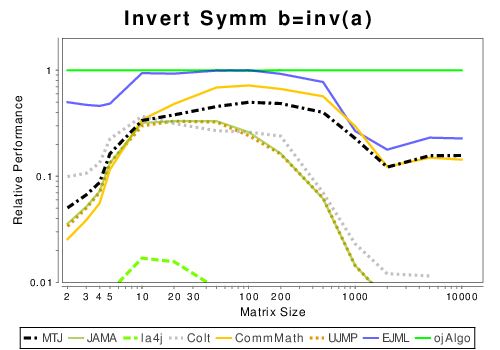
These results show the performance of libraries that have code written entirely in Java.
Java: Basic Operation Results
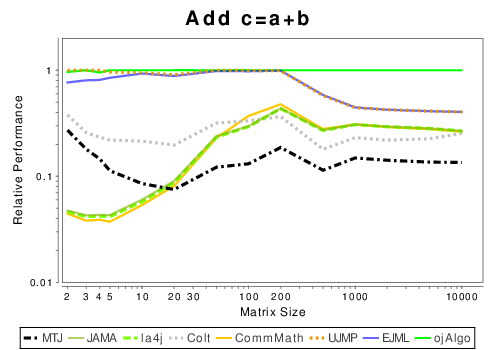 |
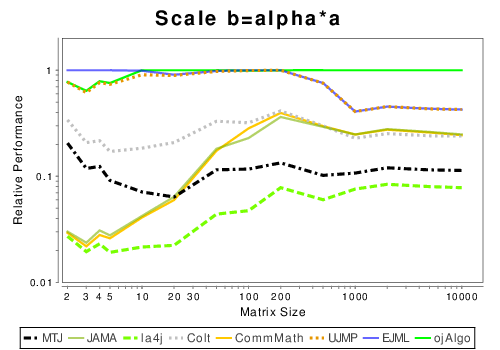 |
 |
|
 |
|
 |
 |
Java: Solving Linear Systems
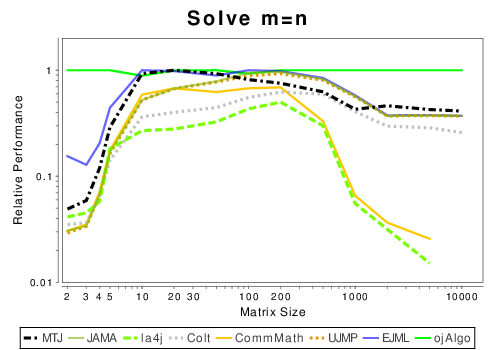 |
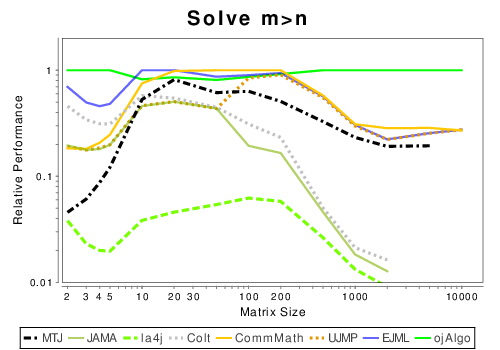 |
Java: Matrix Decompositions
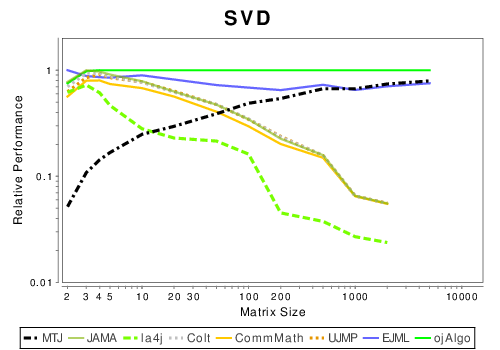 |
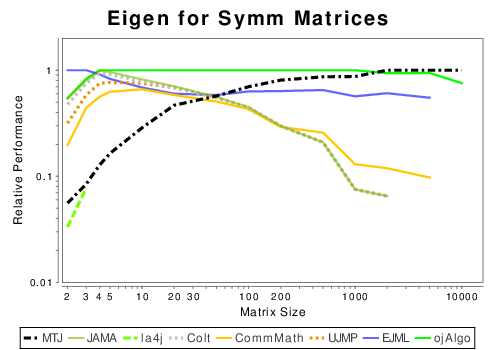 |
Mixed Java and Native Libraries
These results show the performance of libraries that either use pure Java or calls to native libraries.
Mixed: Basic Operation Results
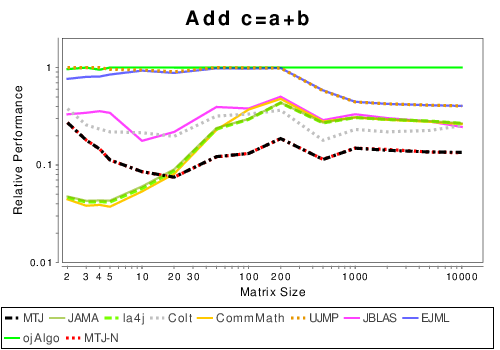 |
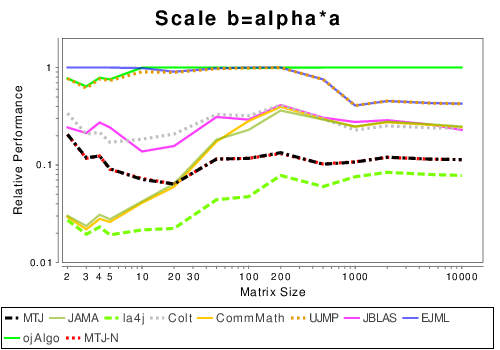 |
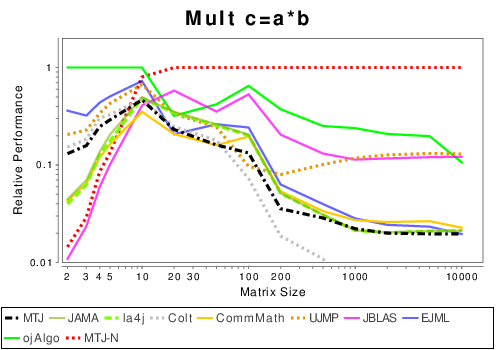 |
|
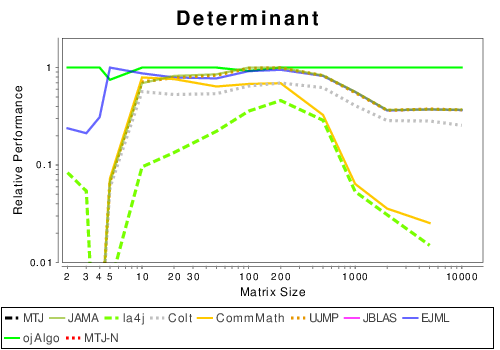 |
|
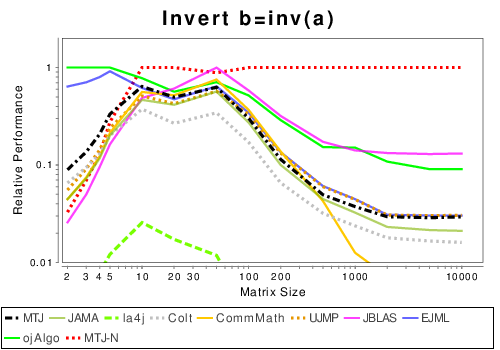 |
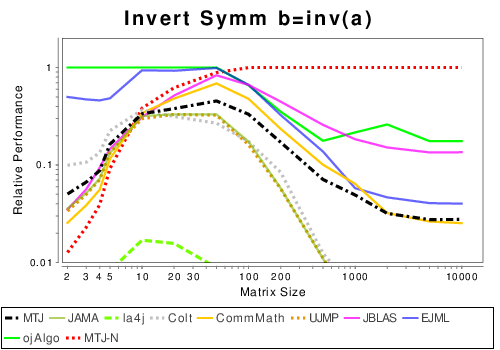 |
Mixed: Solving Linear Systems
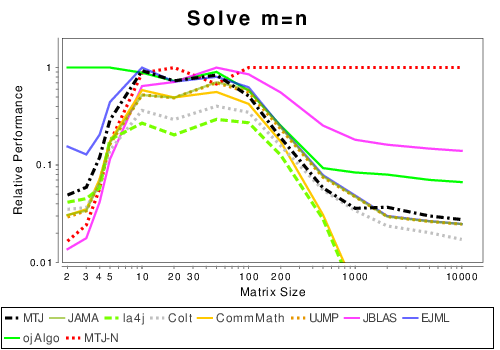 |
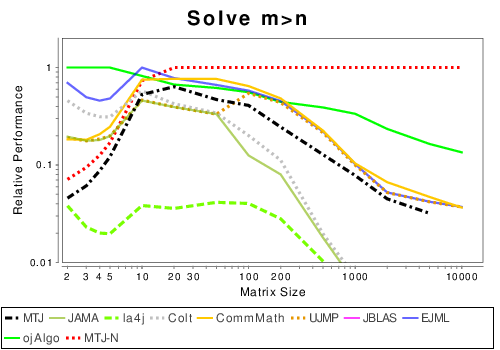 |
Mixed: Matrix Decompositions
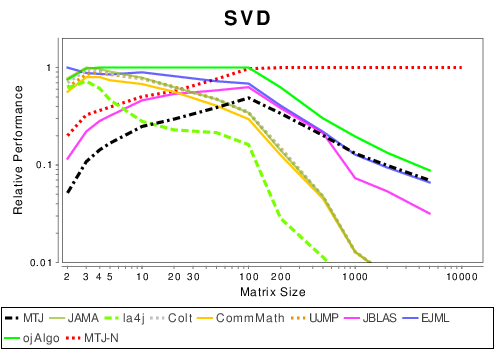 |
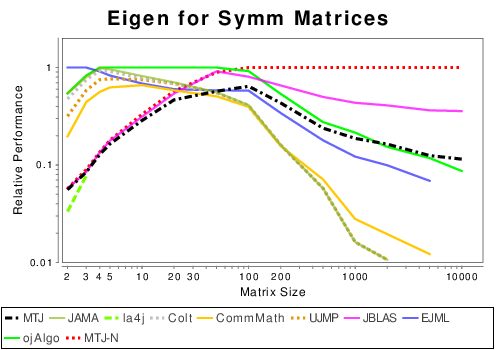 |